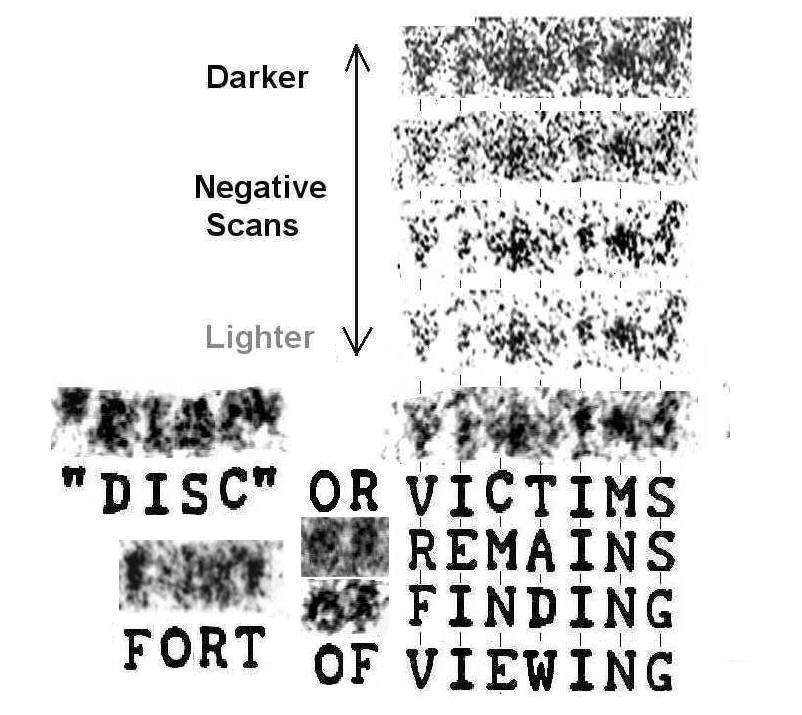
Summary statistics of Randle/Houran study--Bungled statistical analysis, severe experimenter bias, omission of critical findings, and hyping of nonexistent results
Subjects were divided into three groups: a control group told nothing at all, a group given misleading information that this was about atomic testing, and a group given a Roswell context. (What they term the "pro-UFO" condition, another indication of the author's agenda, that subjects told about Roswell would be biased to a pro-alien or saucer crash interpretation, even though many people who might know about the Roswell incident are skeptics, and might be equally biased to an "anti-UFO" interpretation. Why didn't they just call it the "Roswell" group?)
The table at bottom was primarily derived from Randle/Houran's main summary table. A few more items have been added, such as total words read (derived from their word averages times number of subjects) and breakdown by total words and percentages of so-called "common" words, "exclusive" words, and miscellaneous (totally unspecified) words.
Note following things:
Subject motivation obviously low
1. Subjects were not highly motivated. Average study time for all groups was only about 17 minutes, though those given something to work with (atomic bomb, Roswell) worked a little longer than the control group (which spent only 14 minutes average), the Roswell group working longest of all (still only 20 minutes). Poor work materials, noted above, may have helped discourage people. Commonly many subjects for college psych experiments are students doing this as optional homework or extra credit assignment, or recruited by offering a small amount of money. There is little to motivate most of these people, who usually want to put in the mininum time possible. Thus how valid are sweeping conclusions going to be on a very difficult task like this when little time is spent by unmotivated people? Can we validly conclude that people are just "making up things" up or "little can be read" if people spend only 17 minutes on the difficult Sunday New York Times crossword, getting only a few words and disagreeing on some?
2. In addition, there was no test of subject English word skills, which can obviously vary widely. Were ESL English-as-a-second-language subjects mixed in with native English speakers? What was the spread in level of education? Nothing is said. Yet, this is very much a language puzzle. Again, how valid are conclusions about readability if we know nothing about the language competency of the readers?
KEY POINT: Their "priming" or reader bias effect is almost nonexistent
3. Randle/Houran claimed subject condition produced a major "priming" or biasing effect, but provided only 10 words from the two context conditions. Note that some of these words were actually completely neutral ("remains", "fundamental", "morning", "meaning") and others could easily be accommodated in either context. E.g., the neutral "meaning" in the atomic "priming" group was a strong consensus read by supposedly "biased" Roswell readers like myself (in phrase "meaning of story"), and two Roswell researchers also thought quite independently that "atomic" and "laboratory" appeared in the message. (see comparison Ramey memo reads page) Words like "glasses" and "flash" also are not obviously specific to atomic testing, since they could also be easily accommodated in various Roswell scenarios if researchers were simply reading on bias.
4. Thus maybe 4 or 5 words at most that might be considered context-specific or "primed" in both groups. But look at the total number of words read: 271 + 278 = 549 (derived by multiplying average word/person times number of subjects). Thus maybe 1% of the read words seem to be strongly influenced by context. Yet Randle & Houran proclaim they have proven a major "priming" or biasing effect. WHAT????
5. They don't provide the number of instances of so-called "exclusive" words, a very obvious and glaring omission. E.g., how many subjects actually saw "atomic" or "UFO"? We don't know because they don't say. When a referee noted this data was incomplete and asked for further supporting data for their "priming" effect , Randle & Houran admitted that they didn't have the data, that a graduate student supposedly had thrown it away. (Dog ate my homework excuse) The "exclusive" words were the whole basis of their main conclusion that readings were highly biased, yet they didn't have the data to back it up! That should have prompted an instant rejection of the paper, but it didn't. So much for JSE peer review.
6. Chances are most if not all of these GROSSLY OVERHYPED "exclusive" or "bias" words were by single individuals. And as noted, at least half of these words were neutral or not particularly context-specific. So we are again back in the 1% or so range of the words being biased by context. Their "priming" effect is almost entirely non-existent.
Roswell readers much better at picking out "common" words: barely discussed, absurd
rationale provided for result
7. Randle/Houran also noted there were some words that were common across all three groups, and thus even they were forced to admit they were probably there, not just imaginary. (These are also strongly agreed upon by various "biased" Roswell researchers, but only one sentence is devoted to mentioning this in a 20+ page paper.) These are the "common" words. Do you notice a very obvious trend in the data across groups? Look at the total number of common words in the three different groups. Those "primed" with the Roswell "pro-UFO" "bias" were much better at picking out these words than those with the atomic "bias", who were in turn much better than the control group. Obviously proper historical context was extremely helpful to the readers in finding the words that even Randle/Houran admit are there. Knowing that "weather balloons" and "Fort Worth, Tex" are historically part of the Roswell story strongly helps in picking out these words. (Not so obvious is why they were also much better in picking out less context-specific words like "land" and "story", unless they were also thinking of something like a cover story and a flying saucer landing.)
8. Surely Randle/Houran acknowledged the obvious signficance of this result that is so clearly and strongly supported by their data. Not exactly. Instead there was some speculative arguments about how the Roswell group would be more highly motivated and work much harder than the atomic or control group and this alone explains the huge difference. I agree that greater average work time for the Roswell group suggests somewhat greater motivation than the other two groups (20 vs. 16 vs. 14 minutes). But the Roswell group spent only 25% more time than the atomic group, yet they got 150% more of these "common" words. Furthermore, overall (according to the provided statistics) they actually got slightly fewer words per person (4.6 vs. 4.8), not more. If they are spending more time and are more motivated, shouldn't they be getting many more words per person overall just like for the "common words? As is the case with most of their numbers and arguments, Randle/Houran don't make any logical sense at all.
9. What this amounts to is that Randle/Houran are trying to have it both ways. Reading of the miniscule number of "exclusive" words they ascribe purely to reader bias or "priming" by context, but a HUGELY robust improvement of reading of "common" words is supposedly due only to improved motivation and has nothing to do with wise utilization of correct context. Such a logically twisted, inconsistent argument is one of many indications of these researchers' personal bias and debunking agenda.
What are the "all other words" and why didn't they mention them? Perhaps because they
contradicted their conclusions of reader bias and lack of much agreement among readers
10. Also note category "all other words", which make up about half of all read words across groups. However, only ~71 were read for the Roswell group versus ~194 for the atomic group. These values were derived by me by subtracting "common" and "exclusive" words (assuming only 1 instance each) from total words. These are words that are neither "common" or "exclusive". So what exactly are they and why is there such a huge difference between these two groups? Why don't Randle/Houran mention them? Why in this instance are the "less motivated", "less hard-working" atomic group who spent less time fantastically better (>170%) than the Roswell group? This also doesn't make any sense numerically or logically.
11. Undoubtedly these miscellaneous words were extremely common and neutral English words like "the", "and", "of", "at", "for", etc. that make up about 40-50% of the entire message according to various reads (and would be expected to make up a similar percentage of any printed English message), at least some of which should have been relatively easy for people in the various groups to pick out. I find it virtually impossible to believe that some of these words weren't truly common across at least two if not all three groups. These should have been listed among the "common" words. Instead, they appear to have been swept under the carpet. They don't appear directly in their tables at all and are NEVER discussed. Was this done deliberately to minimize the number of such words, which undercut the author's claim that people were just seeing what they wanted to see and little could be reliably read? Or was this just more incompetence by whomever compiled the statistics?
12. Likewise if some of these miscellaneous words were exclusive to one group or another, why aren't they listed in the "exclusive" words? Perhaps because they are completely neutral and independent of context, which would further undermine their argument that readers were highly "primed" or biased by context, supposedly reflected in the "exclusive" words. Whatever, obviously the "priming" effect is largely imaginary.
13. JSE peer reviewers apparently didn't question the various logically inconsistent numbers and arguments either since there is no clarification anywhere. Again, so much for JSE peer review.
More statistical garbage
14. There are other serious problems with their published numbers. They say that "Fort Worth, Tex." and "weather balloons", though naturally occurring together, are treated as two separate words each. In that case, wouldn't "Fort Worth, Tex." better be represented as THREE words, not two? To confuse the issue further, they separate out "weather" and "balloons" as separate in their summary table, but not "Fort Worth, Tex", which is lumped all together, with number of instances for each group (24, 17, 11). In my summary table below, I instead list these as (24x3, 17x3, 11x3) to reflect the total number of actual words, or should it have been (24x2, 17x2, 11x2), even though we are really dealing with three, not two words? However, I have assumed three words in totalling up the total number of "common" words for each group at the bottom, and this is carried through in the other statistics.
15. Though not shown in the table below, their stated standard deviations for number of words read in each group were identical, which is highly improbable (standard deviation is a measure of how widely data varies from average). They also seemed absurdly small (.23 words), which would mean just about everbody in a group read exactly the same number of words. How likely is that? I caught these very obvious mistakes instantly. But Randle/Houran didn't, and neither did sleeping JSE reviewers. In addition, when I studied the "identical" standard deviations more closely, I found they were mathematically impossible, unless they were throwing fractional words into the mix. Houran finally copped to the mistake in a private email to me, provided the corrected standard deviations, and claimed it was a simple oversight. However, it just underscores how sloppy or incompetent they were with their numbers and how bad the review process was.
Experimenter bias: They got the result they wanted even though it didn't exist, ignoring their
own numbers
16. There are many other very, very serious problems with this paper that go beyond the badly flawed experimental design (see above), and the even worse data and statistical analysis. It would take a long paper to detail all the flaws and bias in this study. (A long discussion about this was carried out by me on UFO Updates a few years ago, with Randle & Houran ducking points the whole way.) Randle & Houran state outright that they expected to prove that there was a major "priming" or biasing effect, and then claim that they found it. Only they didn't, and in fact found the exact opposite. This paper is dripping with experimenter bias, what the scientific method and peer review is supposed to minimize. But both failed badly in this case. The basic idea was fine, but the execution of it was a disaster, a good example of very bad science at work.